
Summary
In the last decade, computational literary studies have expanded, yet computational thematics remains less explored than areas like stylometry, which focuses on identifying stylistic similarities between texts. A 2024 study by researchers from the Max Planck Institute and the Polish Academy of Sciences investigated the most effective computational methods for measuring thematic similarity in literary texts, aiming to improve automated genre clustering.
Key Findings and Assumptions
- Key Assumptions:
- Text pre-processing to emphasize thematic content over stylistic features could improve genre clustering.
- Unsupervised clustering would offer a more scalable and objective approach to genre categorization than manual tagging by humans.
- Four genres were selected (detective, fantasy, romance, science fiction) for their similar level of broad qualities.
- If the genres are truly distinct in terms of themes, computers should be able to separate them into clusters.
- Best Performance: The best algorithms were 66-70% accurate at grouping books by genre. Thus showing unsupervised genre clustering is feasible despite the complexity of literary texts.
- Text Pre-Processing: Medium and strong levels of text pre-processing significantly improved clustering, while weak pre-processing performed poorly.
- Which methods worked best: Doc2vec, a method that captures word meaning and context, performed the best overall, followed by LDA (Latent Dirichlet Allocation), which finds major topics in texts. Even the simpler bag-of-words method, which just counts how often words appear, gave solid results.
- Best way to compare genres: Jensen-Shannon divergence, which compares probability distributions, was the most effective metric, while simpler metrics like Euclidean distance performed poorly for genre clustering.
Methodology
Sample Selection
The researchers selected canonical books from each of the four genres, ensuring they were from the same time period to control for language consistency.
Sample Pre-Processing and Analysis
The researchers analyzed all 291 combinations of the techniques in each of the three stages: text pre-processing, feature extraction, and measuring text similarity.
Stage 1: Different Levels of Text Pre-Processing
- The extent to which the text is simplified and cleaned up.
- Weak → lemmatizing (reducing words to their base or dictionary form (e.g., “running” to “run”), removing 100 Most Frequent Words
- Medium → lemmatizing, using only nouns, adjectives, verbs, and adverbs, removing character names
- Strong → Same as medium, but also replaced complex words with simpler versions.
Stage 2: Identifying Key Text Features through Extraction Methods
- Transforming pre-processed texts into feature lists.
- Bag-of-Words → Counts how often each word appears.
- Latent Dirichlet Allocation (LDA) → Tries to discover dominant topics across books.
- Weighted Gene Co-expression Network Analysis (WGCNA) → A method borrowed from genetics to find clusters of related words.
- Document-Level Embeddings (doc2vec) → Captures semantic relationships (connections between words based on their meanings (e.g., “dog” and “cat”)) for similarity assessment.
Stage 3: Distance metric (Measuring Text Similarity)
- Quantifying similarity with metrics. 6 metrics were chosen:
- Euclidean, Manhattan, Delta, Cosine Delta, Cosine, Jensen-Shannon divergence
To minimize the influence of individual books on the clustering results, rather than analyzing the full corpus at once, the researchers used multiple smaller samples. Each sample consisted of 30 books per genre (120 books total), and this sampling process was repeated 100 times for each combination. Additionally, models requiring training (LDA, WGCNA, and doc2vec) were retrained for each sample to reduce potential biases.
Clustering and Validation
The researchers applied Ward’s clustering algorithm on the distances, grouping texts into four clusters based on genre similarity. They then checked how well these clusters matched the actual genres of the books. To do this, they used a scoring system called the Adjusted Rand Index (ARI), which gives a number between 0 (least accurate) to 1 (most accurate).
The results were visualized using a map projection, grouping similar books closer together, and revealing the underlying thematic structures and relationships among the novels.
Core Findings and Figures
Results
The best algorithms grouped literary texts with 66-70% accuracy, demonstrating that unsupervised clustering of fiction genres is feasible despite text complexity. Successful methods consistently used strong text pre-processing, emphasizing the importance of text cleaning and simplification to focus more on a book’s themes rather than its writing style.
Among the top features, six of the ten were based on LDA topics, proving its effectiveness in genre classification. Additionally, eight of the best distance metrics used Jensen–Shannon divergence, suggesting it is highly effective for genre differentiation.
Generalizability
To assess generalizability, five statistical tests were used to analyze interactions between text pre-processing, feature extraction methods, distance metrics, and other factors. These models provided insights into the broader effectiveness of various methods for thematic analysis.
Text Pre-Processing and Genre Clustering
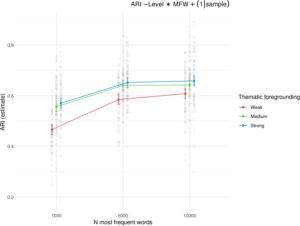
Text pre-processing improves genre clustering, with low pre-processing performing the worst across all feature types. Medium and strong pre-processing showed similar results, suggesting replacing complex words with simpler words offers minimal improvements in genre recognition.
The benefits of strong text pre-processing for document embeddings, LDA, and bag-of-words were minimal and inconsistent. The figure below suggests a positive correlation between Most Frequent Words and ARI and the degree of text pre-processing and ARI. This demonstrates that how we prepare texts matters just as much as what algorithms we use. Moreover, researchers can save time by avoiding replacing complex words with simpler words if medium and strong pre-processing show similar results.
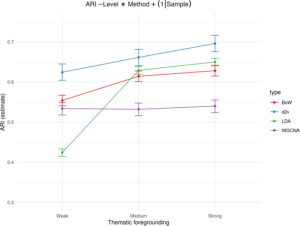
Feature Types and Their Performance
Doc2vec, which looks at how words relate to each other in meaning, performed best on average, followed by LDA, which remained stable across various settings, such as topic numbers and the number of Most Frequent Words. Perhaps researchers can use this method without excessive parameter tuning. The simple bag-of-words approach performed well despite its low computational cost, perhaps suggesting even basic approaches can compete with more complex models. WGCNA performed the worst on average, suggesting methods from other fields need careful adaptation before use.
LDA Performance and Parameter Sensitivity
The performance of LDA did not significantly depend on the number of topics or the number of Most Frequent Words being tracked. The key factor influencing thematic classification was text pre-processing, with weak pre-processing significantly reducing ARI scores. Hence, this underscores the need for further research on text pre-processing, given its key role in the effectiveness of LDA and overall genre classification.
Bag-of-Words Optimization
The effectiveness of Bag-of-Words depended on a balance between text pre-processing and how many Most Frequent Words are tracked. While increases in Most Frequent Words from 1,000 to 5,000 and medium text pre-processing significantly improved accuracy scores, further increases provided minimal gains. This ‘sweet spot’ means projects can achieve good results without maxing out computational resources, making computational thematics more accessible to smaller research teams and institutions.
Best and Worst Distance Metrics for Genre Recognition
Jensen–Shannon divergence, which compares probability distributions, was the best choice for grouping similar genres, especially when used with LDA and bag-of-words. The Delta and Manhattan methods also worked reasonably well. Euclidean was the worst performer across LDA, bag-of-words, and WGCNA despite its widespread use in text analysis, suggesting further research is needed to replace industry-standard metrics. Cosine distance, while effective for authorship attribution, was not ideal for measuring LDA topic distances. Doc2vec is less affected by the comparison method used.
Main Findings
Unsupervised learning can detect thematic similarities, though performance varies. Methods like cosine distance, used in authorship attribution, are less effective for thematic analysis when used with minimal preprocessing and a small number of Most Frequent Words.
Reliable thematic analysis can improve large-scale problems of inconsistent manual genre tagging in digital libraries and identifying unclassified or undiscovered genres. Additionally, it can enhance book recommendation systems by enabling content-based similarity detection instead of solely relying on user behavior. Much like how Spotify suggests songs based on acoustic features.
Conclusion
This study demonstrates the value of computational methods in literary analysis, showing how thematic clustering can enhance genre classification and literary evolution. It establishes a foundation for future large-scale literary studies.
Limitations
Key limitations include the simplification of complex literary relationships in clustering, which despite reducing complex literary relationships into more manageable structures, may not work the same way with different settings or capture every important textual feature.
The study also did not separate thematic content from elements like narrative perspective. Additionally, genre classification remains subjective and ambiguous, and future work could explore alternative approaches, such as user-generated tags from sites like Goodreads.
Implications and Future Research
This research provides a computational framework for thematic analysis, offering the potential for improving genre classification and book recommendation systems. Future work should incorporate techniques like BERTopic and Top2Vec, test these methods on larger and more diverse datasets, and further explore text simplification and clustering strategies.
Bibliography
Sobchuk, O., Šeļa, A. Computational thematics: comparing algorithms for clustering the genres of literary fiction. Humanit Soc Sci Commun 11, 438 (2024). https://doi.org/10.1057/s41599-024-02933-6
Book genres. (2022). Chapterly. Retrieved May 4, 2025, from https://www.chapterly.com/blog/popular-and-lucrative-book-genres-for-authors.