Incredible advancements in artificial intelligence (AI) have recently paved the way for the use of AI in healthcare settings. Implementation of AI has the potential to address worker shortages in the medical field, lead to discovery of new drugs, or improve diagnoses (Bajwa et al., 2021). A writer for the American Medical Association, Benji Feldheim applauds AI for restoring the “human side” in medicine. For example, AI scribes in particular ease the documentation burden doctors face—reducing burnout and improving doctors’ interactions with patients as a result (Feldheim, 2025). Another example is the AI model developed by Shmatko et al. (2025), known as Delphi-2M, which is capable of accurately predicting a patient’s next 20 years of disease burden (i.e., what diseases they would contract and when). Evidently, AI is a very promising technology already capable of improving lives, however, there are reasons to be skeptical. While these advances are promising, these uses of AI also raise concerns about fairness and clinical safety. After a brief synopsis of Shmatko et al.’s Delphi-2M, I evaluate the ethical ramifications of AI-powered diagnoses and related clinical tools.
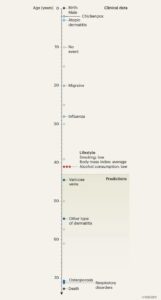
Delphi-2M is an AI model trained on over 400,000 patient histories from a UK database to forecast an individual’s 20-year disease trajectory. Similar to chatbots like ChatGPT, Delphi-2M is a large language model (LLM), a type of AI that can recognize and reproduce patterns from large amounts of data. Similar to how chatbots pick up on what words are likely to appear with other words in order to form sentences, Delphi-2M learns from its vast training set of medical records to predict a patient’s disease trajectory from realworld patterns. As Yonghui Wu puts it in her summary of Shmatko et al.’s work, it’s just how becoming a smoker may be followed by a future diagnosis of lung cancer—these are patterns Delphi-2M recognize. To do this, Delphi-2M is fed “tokens” that link diseases or health factors to specific times in a person’s life, like chickenpox at age 2 or smoking at age 41 (Figure 1). Then, Delphi-2M outputs new tokens that predict what diseases and when they will occur in an individual’s life, like the onset of respiratory disorders at age 71 as a result of smoking. Delphi-2M, after being trained, was tested by predicting the medical histories of 1.9 million patients not included in the original training set. Shmatko et al. demonstrate this AI to have great success in accurately predicting disease trajectory, as it partially predicts patterns in individuals’ diagnoses in 97% of cases.
Nonetheless, we must hold AI used to diagnose patients to a higher level of scrutiny compared to AI used commercially. LLMs are not perfect as they are subject to algorithmic bias and misuse, beginning before their creation. Shmatko et al. (2025), for example, address some shortcomings of the training data used for Delphi-2M. Notably, they explain the data from a mostly-white, older subset of the UK population isn’t entirely generalizable to very different demographics. Though Shmatko et al. found successes testing the model against a Danish database after training it on UK patients, I’m still concerned how Delphi-2M would perform on non-European and younger demographics, or those underrepresented in training data. Facial recognition is a prime example of where AI underperforms when training datasets lack diverse representation. AI designed to recognize faces historically underperform on individuals with feminine features or darker skin due to unrepresentative training data (Hardesty, 2018). With this in mind, it’s important that training data for diagnostic AI is representative of all demographics prior to widespread implementation.
Furthermore, Cabitza et al. (2017) wrote on some of the unintended consequences of machine learning in healthcare, postulating that widespread implementation of these tools also has the potential to reduce the skill of physicians. Though convenient in the short run, Cabitza et al. raise concerns with overreliance on AI—as studies show physicians aided by AI were less sensitive and accurate in diagnosing patients. Mammogram readers, for instance, were 14% less sensitive in their diagnostics when presented with images marked by computer-aided detection (Povyakalo et al., 2013). Though this study focused on image diagnoses, it’s clear how widespread use of Delphi-2M would lead to the same problems of deskilling in physicians. Delphi-2M is also exclusively a text-based model, which as Cabitza et al. detail, means that these diagnosis algorithms do not incorporate crucial contextual elements that are “psychological, relational, social, and organizational” in nature. A realworld example that Cabitza et al. described was an instance in which an AI model predicted a lower mortality risk for patients with pneumonia and asthma compared to those with pneumonia and without asthma. Understanding that asthma is not a protective factor for pneumonia patients, the involved researchers found the discrepant AI output was the result of hospital procedures that admitted pneumonia patients with asthma directly to intensive care, giving them better health outcomes. This missing piece of crucial information, which was difficult to represent in these prognostic models, led to an error a physician would not make. Thus, AI is limited in what information it can train on.
Though these new advancements in healthcare AI are promising, they have their limits. Tools like Delphi-2M spot patterns across vast clinical histories that no single clinician could feasibly track, yet the benefits depend on who is represented in the data, how predictions are explained and used, and whether safeguards are in place when they fail. Before AI is implemented in healthcare, we must demand representative training sets, validation across diverse populations, clear disclosures of uncertainty and limitations, and constant human involvement in the process that resists automation bias and deskilling. In short, diagnostic AI should supplmenent—not replace—clinical judgment, and it should be developed with privacy, equity, and patient trust at the forefront. Only then will these systems reliably improve care rather than merely appear to.
References
Bajwa, J., Munir, U., Nori, A., & Williams, B. (2021). Artificial intelligence in healthcare: transforming the practice of medicine. Future Healthcare Journal, 8(2), e188–e194. https://doi.org/10.7861/fhj.2021-0095
Cabitza, F., Rasoini, R., & Gensini, G. F. (2017). Unintended consequences of machine learning in medicine. JAMA, 318(6), 517. https://doi.org/10.1001/jama.2017.7797
Feldheim, B. (2025, June 12). AI scribes save 15,000 hours—and restore the human side of medicine. American Medical Association. https://www.ama-assn.org/practice-management/digital-health/ai-scribes-save-15000-hours-and-restore-human-side-medicine
Hardesty, L. (2018, February 11). Study finds gender and skin-type bias in commercial artificial-intelligence systems. MIT News. https://news.mit.edu/2018/study-finds-gender-skin-type-bias-artificial-intelligence-systems-0212
Povyakalo, A. A., Alberdi, E., Strigini, L., & Ayton, P. (2013). How to Discriminate between Computer-Aided and Computer-Hindered Decisions. Medical Decision Making, 33(1), 98–107. https://doi.org/10.1177/0272989×12465490
Wu, Y. (2025). AI uses medical records to accurately predict onset of disease 20 years into the future. Nature, 647(8088), 44–45. https://doi.org/10.1038/d41586-025-02971-3